
A few weeks ago, I wrote the first of three posts on my key takeaways from the Gartner Analytics conference. The first message focused on Organizing the Chaos. It’s taken me a bit longer than anticipated to write post no 2 on governing self-service BI. However, hopefully it was worth the wait because I will tie back to a post I wrote on Spotfire Skills – Historically Speaking. In this week’s post, I will explain more about the skills users will need to have in the immediate future. Read on to find out what you can do to put a guard rail around self-service analytics.
Self-service BI has become an essential part of analytics architecture, but self-service is a bit of a Pandora’s Box — a source of great and unexpected troubles. Sure, it can help users get their data faster than the traditional BI model where requests are funneled to IT, and IT delivers something that may or may not be what the user asked for 6 months later. But, the speed of self-service often comes at a price because we can’t get away from the reality of delivering data.
The Reality of Delivering Data
(3 Paths to Delivery)
- Fast and wrong
- Slow and right
- Slow and wrong (also an option)
Unfortunately, fast and right is generally not an option (if only). If left un-governed, self-service turns into a hot mess quickly. Next thing you know you start seeing the problems below.
- Duplicate data sets
- Abandoned data sets
- Incorrect data sets
- Temporary data sets that become permanent, possibly supporting critical business processes
If decisions are being made with self-service data, there needs to be a degree of confidence and assurance it is correct. Thus, we need to really think about governing self-service BI.
New Ideas
The road to governing self-service BI has three discussion points.
- Data Pipeline
- DataOps
- Roles in DataOps
The Data Pipeline
First, I want to talk about the data pipeline and the lifecycle of a data set in terms of who interacts with it, when, and how. I’ve included a slide below from Joao Tapadinhas’ presentation “How to Start, Evolve and Expand Self-Service Analytics”. He was one of my favorite presenters at the conference.
This provides an example of a data pipeline. You can see the data moves from the source to different locations, interacts with different roles, goes thru a certification and promotion process and ultimately supports support dashboards and interactive visualizations. The data set lifecycle is represented by the Certification and Promotion process. It’s not explicitly written, but if a data set isn’t certified and promoted, it has two other paths — end of life or review at a time interval.
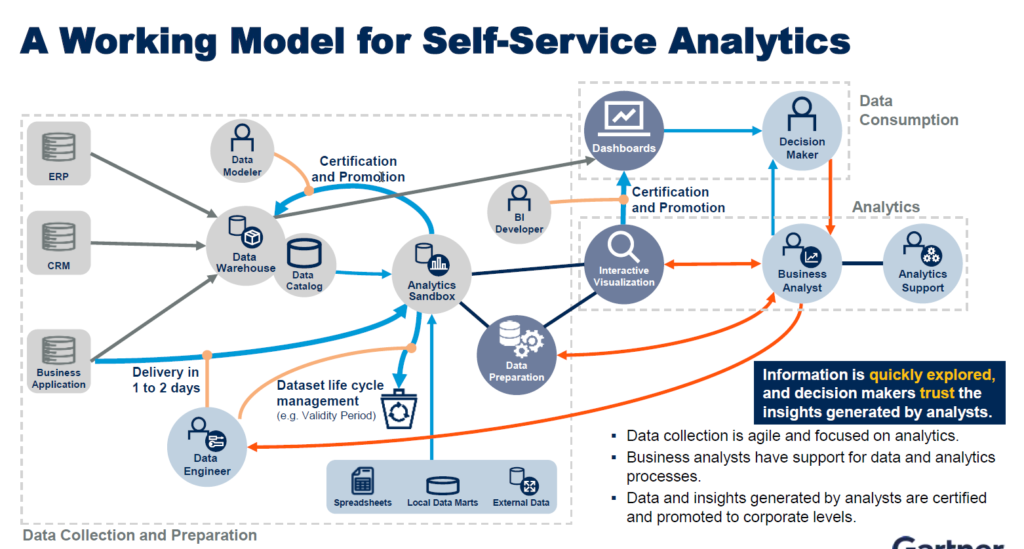
Governing the Sandbox
The certification and promotion process is what self-service governance is all about. The data starts in the source application. It flows to the data warehouse, but also to an analytics sandbox.
To clarify, a sandbox is a place for user experimentation and discovery, and it can take many forms. It could be a SQL server that users are allowed to write to and pull from without going thru IT processes. You might also think of Alteryx as an analytics sandbox. Yes, it’s an application. But, it’s where users perform self-service on data sets of interest.
If you find something good, the data set can go thru a certification and promotion process and find a permanent home in the data warehouse rather than a “temporary” one in the sandbox. At that point, the data set becomes part of a formal data management process ensuring the data sets being used in decision making are reliable and correct.
It’s a beautiful mix of allowing users to experiment and build on their own but also incorporating those creations into a broader ecosystem. With this type of model, you can have an architecture whereby information is quickly explored, and decision makers trust the insights generated by analysts. Data collection is agile and focused on analytics. Business analysts have support for data and analytics processes. Data and insights generated by analysts are certified and promoted to corporate levels.
So, this is all fine and grand, but how do you actually implement it.
DataOps
To implement such an architecture, you need DataOps. Pivotal to DataOps is the idea that data is a PRODUCT and should be managed as such. Nick Heudecker presented “Your Data Culture is Changing – Do You Need DataOps?”. He defined DataOps as follows:
DataOps is a collaborative data management practice focused on improving the communication, integration, and automation of data flows between data managers and data consumers across an organization.
Nick Heudecker
Now, Nick’s presentation didn’t dive much deeper into what DataOps is, but the DataOps Manifesto lays out 18 Core Principles.
- Continually satisfy your customer
- value working analytics
- Embrace change
- It’s a team sport
- Daily interactions
- Self-organize
- Reduce heroism
- Reflect
- Analytics is code
- Orchestrate
- Make it reproducible
- Disposable environments
- Simplicity
- Analytics is manufacturing
- Quality is paramount
- Monitor quality and performance
- Reuse
- Improve cycle times
Now, that’s just the summary points. Click on the link for details, and you can even sign the manifesto at the bottom. I LOVE these principles. They feel like everything that’s been missing. So, how do we make them a reality? Well, we are going to need some new roles.
Roles in DataOps
Implementing the principles and governance we just discussed will require new roles and responsibilities. I attended three different presentations that all touched on this subject.
- “Your Data Culture is Changing – Do You Need DataOps” by Nick Heudecker
- “The Foundation and Future of Roles and Responsibilities: From Control to Collaborate” by Jorgen Heizenberg
- “Driving Analytics Success with Data Engineering” by Roxane Edjlali
These presenters mentioned several different roles — Data Modeler, Information/Data Architects, SME, Policy/Data Owner, CDO, CIO, Business Process Analytics, Data Broker Manager, Information/Data Steward, Process Owner, Data Engineer, Citizen Data Scientist, Data Scientist, and Data Product Manager.
Let’s focus on the short and medium term. I think the Data Engineer is absolutely critical to deploying any self-service governance. I think the Data Product Manager will be critical to building a high-quality analytics program in a data-centric organization.
Data Engineers — The New Unicorns
Several presenters named the Data Engineer as the new unicorn, the new sexy role. Apparently, it has been decided that we’ll never have enough Data Scientists, so Data Engineer = Unicorn. (I consider myself a Data Engineer, so I’ll take it!)

What does the Data Engineer do? At a high level, the Data Engineer manages the data pipeline and the dataset lifecycle. Thus, the Data Engineer plays a critical role in self-service governance.
At a more detailed level, Roxane’s presentation listed these roles and responsibilities for Data Engineers.
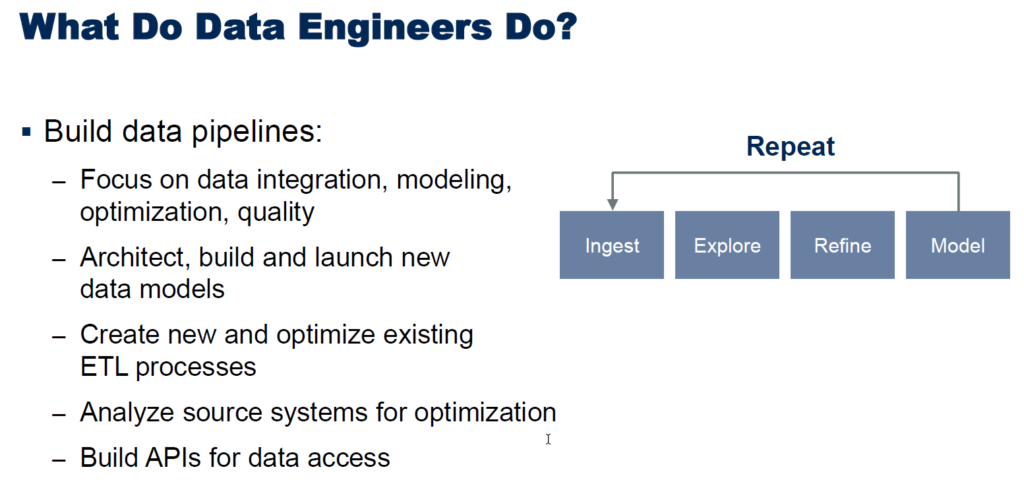
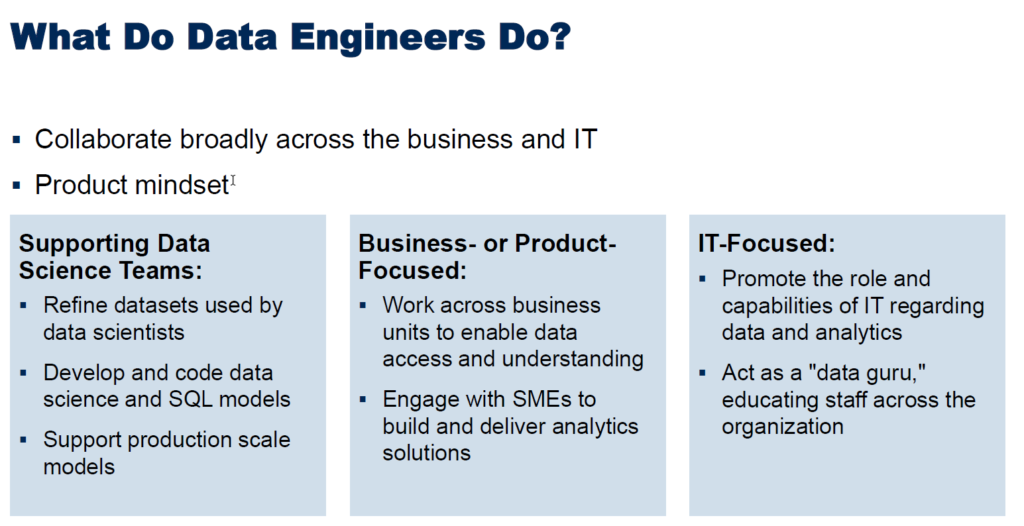
Data Engineers need a broad range of skills, but you can pull people from IT or the business or other domains and develop the skills they don’t have. That’s why the role of the Data Engineer is so exciting. Or, I’m just a big nerd (a distinct possibility).
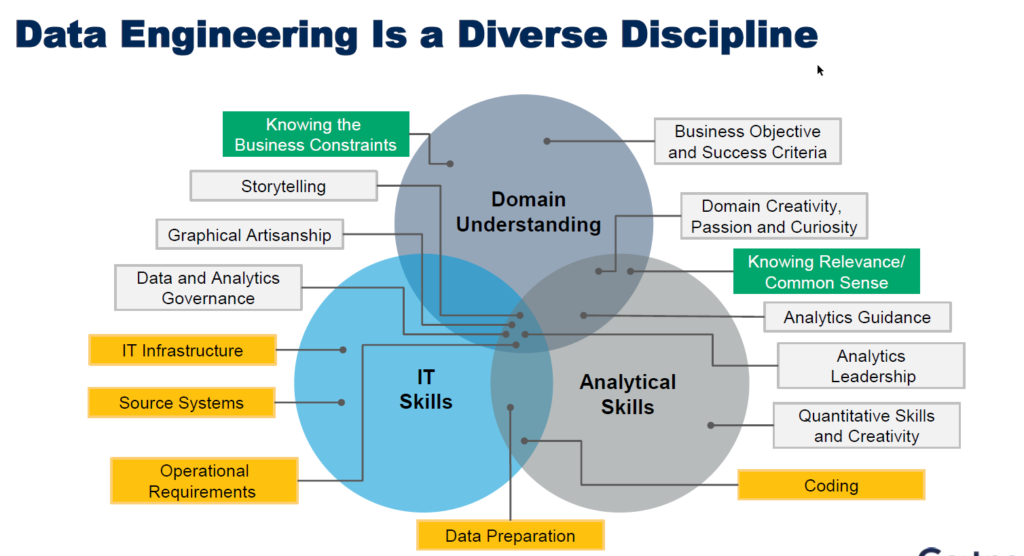
The next role and last piece of this lengthy blog post is the Data Product Manager.
Data Product Managers
Nick Heudecker’s presentation on DataOps introduced the role of the Product Manager. The idea is simple — data is a product and should be managed as such. This falls in line with the DataOps manifesto principle 14 – Analytics is manufacturing.
So what does a Data Product Manager do? Nick’s presentation didn’t specify what a Data Product Manager does, but he did list characteristics of a Data Product Manager.

A little bit of thought and additional research yielded a few bullet points on what a Data Product Manager would do (hint: it has a lot to do with governing self-service BI)…
- Develop a data strategy
- Develop the product, including managing the scaling of analytics by adding more data streams, capabilities, outcomes or new roles (discussed in key message 1)
- Build capabilities with their product
- Measure the usage of data sets
- Ensure data literacy throughout the organization
- Manage Data Engineers
- Marketing
If you want to dive deeper, check out this Medium post on the Rise of the Data Product Manager. In my opinion, it’s a role to manage all the “pie in the sky” things we really want to do with data. Lastly, I’ll just say that if you have a Data Product Manager, you can have metrics. When you know who is using what data, it can be better managed and utilized.
Conclusion
In summary, governing self-service BI is an important topic all organizations must address. It can be governed by introducing DataOps to manage data as it moves thru the data pipeline. New roles like that of the Data Engineer and the Data Product Manager will be critical to establishing and maintaining governance. I’d love to hear your thought in the comments.
Pingback: Key Messages from the Gartner Analytics Conference -- Make Efficient, Automate, Then Innovate • The Analytics Corner
Pingback: Organizing Analytics Chaos » The Analytics Corner
Pingback: 5 Ways to Increase Speed of Delivery » The Analytics Corner
Pingback: Key Messages from the Gartner Analytics Conference » The Analytics Corner