
Occasionally, I take requests for blog posts. A user reached out to me this week and asked if I have any Spotfire library best practices.
Have you written any blogs or do you have any good resources with regard to Spotfire library best practices and folder structures? We are spinning up a new server at my current company and I want to make sure to architect it correctly for sustainability. I really enjoy your content. Thanks!
Well, thanks! I have not written about this subject, but I do have lots of thoughts on the matter. I created our Spotfire library roughly 6 years ago, and while I have made small changes, the structure has stood the test of time with very few regrets. I’ll start by showing you what my library looks like. Then, I’ll lay out 7 Spotfire library best practices, including my naming conventions.
7 Spotfire Library Best Practices
The is the top level of my library.
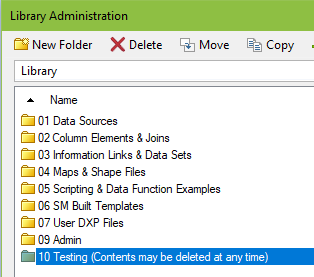
And these are the best practices that went into it.
- Create separate folders for admin use and make sure folder permissions are granted to administrators only.
- Establish, stick to, and police a naming convention for column elements, information links, and enterprise data connections.
- Create one place for users to find data sets, and keep it separate from DXPs.
- Consider how users will search for data sets (i.e. by function, by data source) when building your folder structure.
- Provide users with an organized space to save their work, and don’t let them save or organize anywhere else.
- When deciding whether or not to create new folders, remember, administrators grant permissions at the folder level. If you want to protect something, it must either inherit permissions from a parent folder or be placed in its own folder with specific permissions.
- Create spaces for different categories of work like templates or example files.
Let’s look at each of these in detail.
1. Admin Use Only
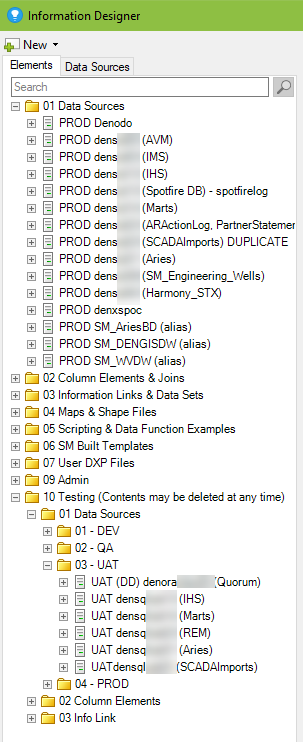
In the screenshot below, I’ve circled folders created for admin use only. I save data sources, column elements, and joins used to build information links in the first two folders. As you can see in the second screenshot, general users cannot modify the contents.
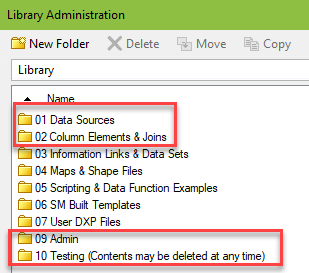
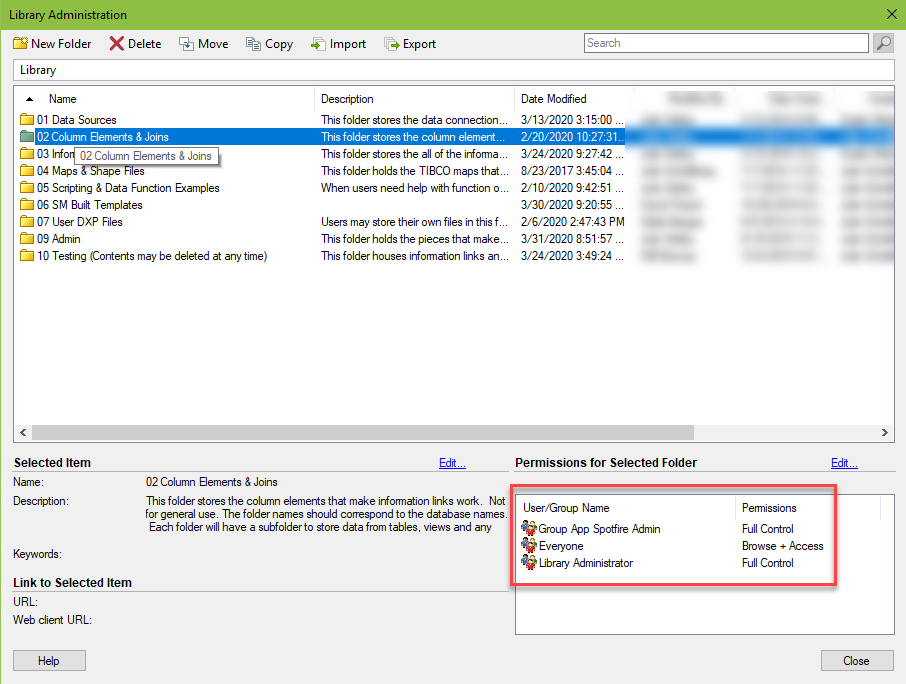
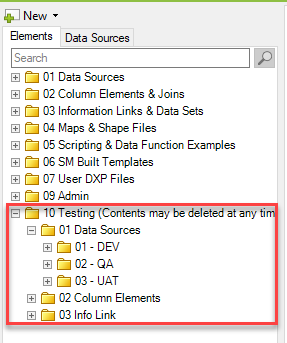
I also have two other admin folders – 09 Admin and 10 Testing. Admin holds automation services jobs and DXP files used specifically by administrators to look at logging and other data. Testing holds nonproduction data sources and column elements, as well as any production information links that are still a work in progress. I like to keep production and nonproduction data sources far away from each other to prevent errors.
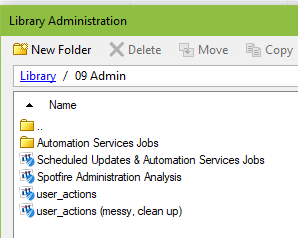
2. Naming Conventions
There are very few things I am as adamant about as naming conventions. My coworkers might even call me belligerent or anal-retentive. But, all of my rules help administrators quickly identify an information link’s source, as well as provide visual controls to help prevent errors.
THE RULES
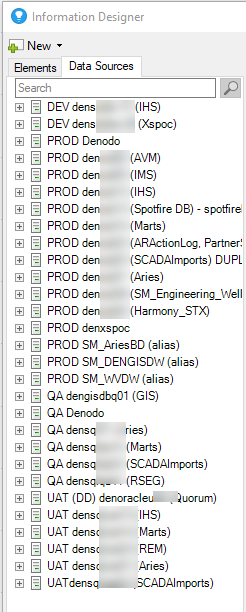
- Create one and only one data source per server. Do not duplicate data sources! (Unless, the database is using an alias, in which case one data source per database.)
- Include the environment, server name, and database name (optional, depending on how many databases are on a server) in the data source name. This provides visual control to prevent errors and make it easy to find what you are looking for quickly.
- Keep PROD data sources separate from QA, UAT, etc data sources. Physical separation is a good barrier against accidentally grabbing column elements from the wrong data source.
- Create one folder for each database in a data source. Name the folder exactly as the database is named.
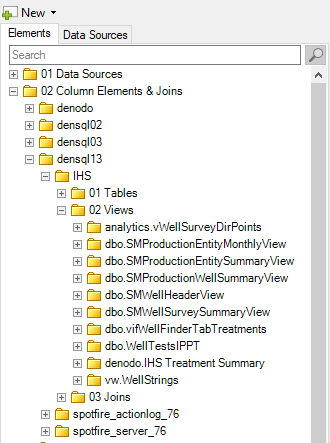
- Provide subfolders to separate column elements from tables and views. For a while, we had many views and tables with the exact same name, so the only way to help the administrator know what they were pointed to was the folder structure.
- Create one subfolder for each view or table. Name the folder with the “schema.exact table/view name” like “dbo.Monthly_ProductionVolumes”.
- Column elements must be named exactly as they exist in the database.
- If you want to rename a column element, create a duplicate column element, and place it in a separate folder called “Modified column elements”.
- Information links can be named whatever you want. Finally, some leeway!
Side Note
Before moving on, I just want to note that I have considered combining the 02 Column Elements and 03 Information Links & Data Sets folders to speed up creating information links. When I first began with Spotfire, I created information links one at a time. Creating folders and moving stuff around wasn’t a big deal. However, as we integrated data virtualization and data warehouses, I found myself creating batches of information links. Spotfire has a right-click option in the Information Designer that makes info link creation very fast. But, it puts your link and column elements in the same folder. Watch this 30-second video for a demonstration.
Ultimately, I kept what I had because even combining those folders would still require a lot of dragging and dropping to keep it clean and organized.
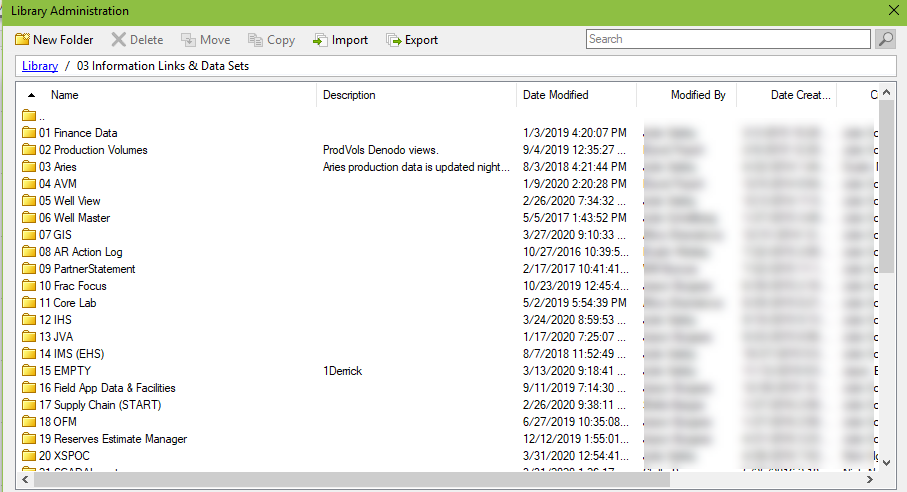
3.Single Location for Data Sets
You want users to easily be able to find what they are looking for. The surest way to do that is to provide one location and keep it clear of clutter. As you can see, I have one folder for all data sets, which leads me to the next best practice…
4. Searching for Data Sets
I organized the 03 Information Links and data sets folder by data source because that is how our users look for data. I briefly thought about reorganizing the library by function so that the drilling people could go to one folder for all their data, and the completions people could go to one folder for the completions data. However, we blend most data sets. A data set may have drilling, completions, reservoir, and production data. Thus, that organization structure would get complicated quickly. So, I kept what we have. You’ll have to take into consideration how your users will search for data.
Additionally, I highly recommend organization by data source because it makes it easy to track down all info links connected to a single source. You’ll want this is you have large scale changes in architecture. For example, we used to connect information links directly to the WellView database. Now, we connect to the WellView data warehouse. Because info links were organized by data source, they were in one place and easy to find. If I had organized the library differently, finding every info link connected to WellView would have been a nightmare.
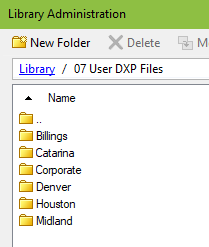
5. An Organized Space for Users
Next, you don’t want users saving just anywhere, so you must give them an organized space to work with. That is why I have the 07 User DXP Files folder, with a subfolder for each office. Next, you need to think about permissions.
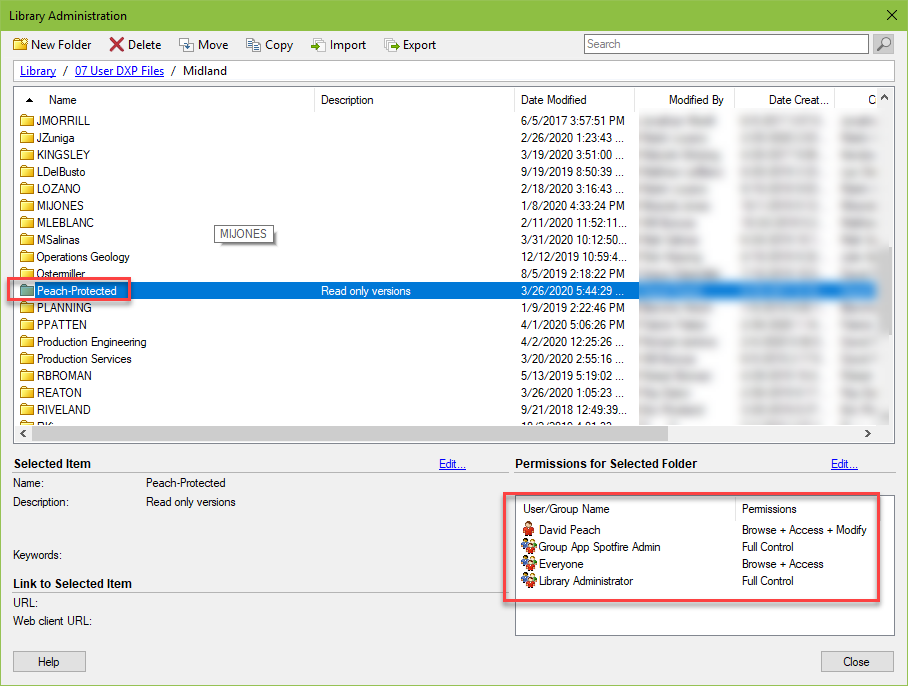
6. Permissions
Spotfire grants permissions at the folder level. A subfolder does NOT have to inherit the permissions of the parent folder. But, if you want to be able to break apart permissions (by team, user, or data set), you must create new folders. For example, within the office subfolder, users can create folders for themselves, for teams, or for specific projects. Then, each folder can be protected as needed.
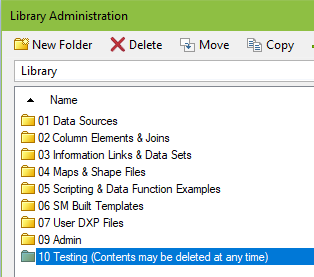
7.Categories of Work
Lastly, provide a space to save other types of work, such as templates or 3rd party products. Here you can see I have created folders for map, scripts, example files, and templates. This one is all up to you to create!
Conclusion
To wrap up, I just want to say that no matter what you put into place, you’ll have to watch it and tend to it. In writing this post, I found several things that needed to be corrected in my library, including DXPs saved in the information links folder. Please use the comments section to share any of your own Spotfire library best practices.
Spotfire Version
Content created with Spotfire 10.2.
Pingback: Positioning Labels on Feature Layers in Spotfire Maps » The Analytics Corner