This is post four in my series on learning to use Microsoft Azure DevOps to manage analytics assets. Last week, I posed five questions to ask and answer before configuring ADO, so that you don’t have rework as I did. Now, we’re going to talk about configuring Microsoft Azure DevOps, specifically the organization, area paths, teams, and iterations. Read on to learn more.
Before starting, I want to recap where we are at in this Azure DevOps series.
- Managing Analytics Assets with ADO (aka how my org works and why we need ADO)
- Azure DevOps Terminology and Structure (so you know what we are talking about)
- Questions to Ask and Answer Before Configuring DevOps (so you don’t have rework like I did)
Hopefully, you read post 3. You asked and answered those 5 questions and are now ready to get started.
The Organization
Before we get into the nitty-gritty of Teams, Area Paths, and Iterations, I need to say something about the organization. My company made the decision to have one and only one organization. We did so for the following security and ease of use reasons (not cost).
- An organization level security settings controls visibility of projects within the organization. If set to “Public Projects”, all projects in the org are exposed to the great wide world, not just your company. We definitely don’t want this. We also don’t want to have to police the security settings of multiple orgs, so one org it is.
- Second, querying, linking and moving work items between projects in the same organization is easy. It’s not easy to do so across different organizations.
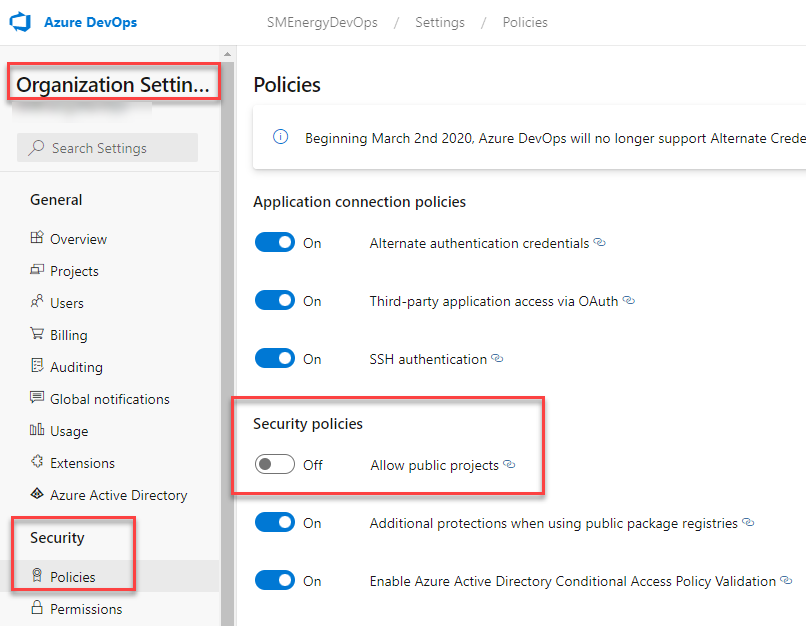
In fact, our GIS team was an early adopter of ADO. They set up their own organization because we didn’t have a formal structure yet. Later, all their work items had to be moved into a different organization, which wasn’t an easy or pleasant process.
Ultimately, the organization is just another way to organize within ADO. Your company may decide differently.
I will say that having an entire company’s worth of projects in one organization does cause a bit of clutter.
Configurating Teams
Misconfiguring my teams was the biggest mistake I made in my first attempt at ADO setup. When I first started working with ADO, I didn’t know why I would want more than one team. I only work with one team, so I only set up one team. I should have thought of the team as just another way to break down and organize all the things in ADO.
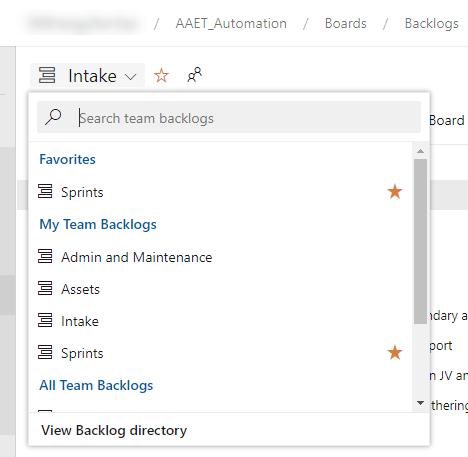
It wasn’t until I saw a coworker use the drop-down within the Backlog board that I realized how teams can be used more effectively. Because ADO creates one backlog for each team, you can set up a team for each distinct type of work and then use the drop-down to toggle back and forth rather than clutter up a single backlog.
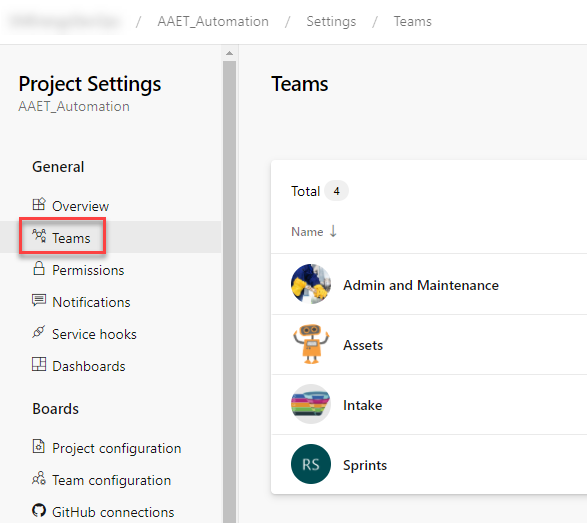
Create teams in Project Settings.
As you can see, I have chosen to use teams to separate Admin and Maintenance work from Analytics Assets from proposed projects (aka Intake). Lastly, you can also query by teams in ADO, which will be the subject of a future post.
Configuring Area Paths
Area paths are another piece of structure you can use to organize within ADO. In the screenshot below, you can see that we are using area paths to track which environment an automation is currently staged in.
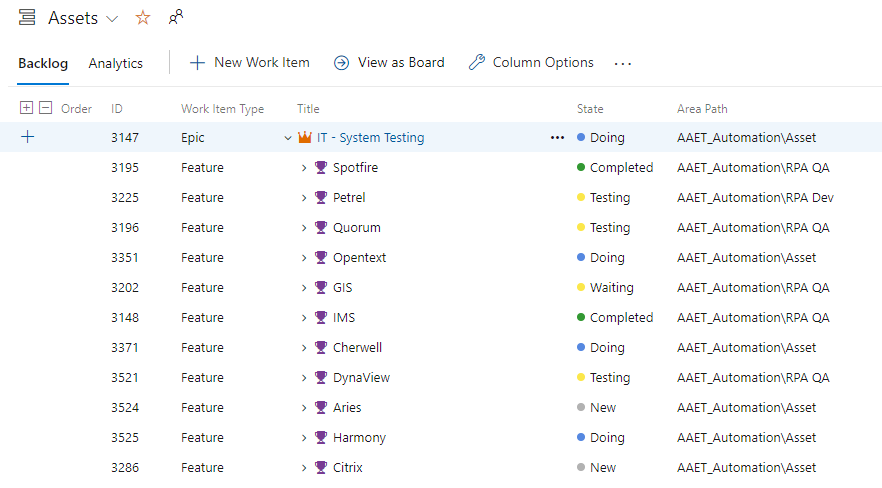
Area paths are set up from within Project settings > Project configuration > Areas.
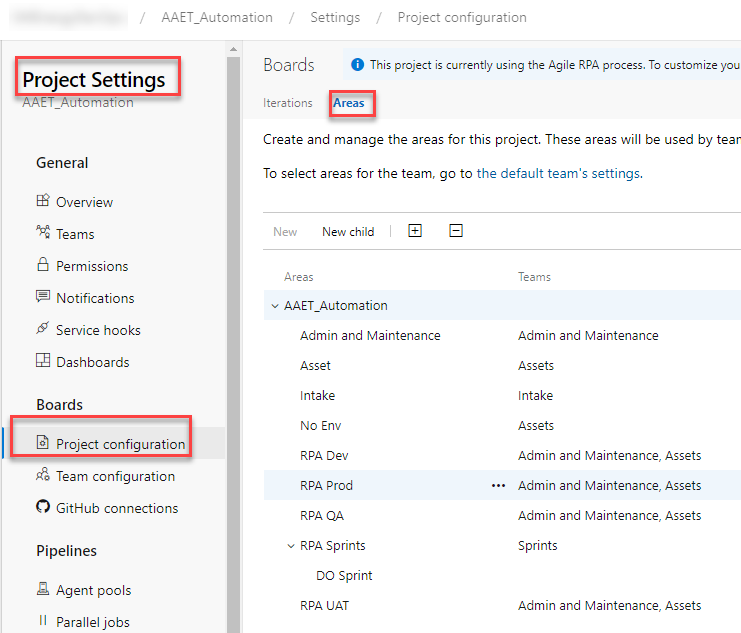
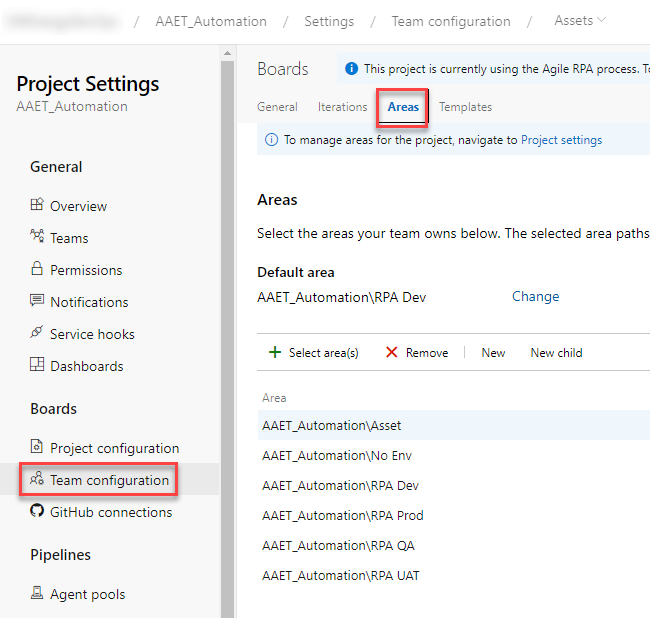
But, in order to be used with a given team, the area path must be mapped to the team. Mapping happens in Team configuration. From within Team configuration select the team and then go to Areas as shown below. Thus, you can create as many area paths as you want but then pick and choose which teams to use them in.
Configuring Iterations
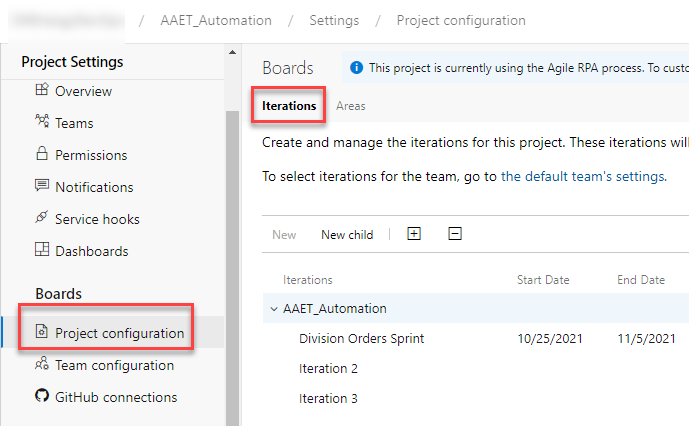
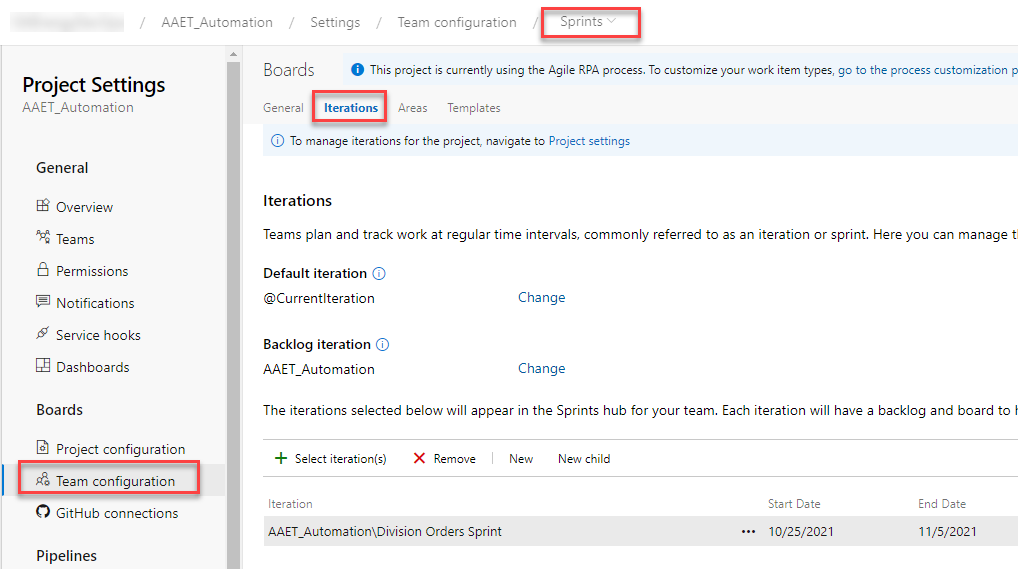
Lastly, we have iterations. Iterations are very straightforward. They are meant to reflect sprints, which are usually 2 weeks at a time. The iteration is the start and end date of the sprint. Iterations are also setup the same way as area paths. You create them from Project configuration within Project settings and then map them to the teams they will be used with in Team configuration. If you are not sprinting, you don’t need iterations.
Conclusion
Before I wrap up this post, I want to give you one more piece of advice. As you are configuring the organization, team, area path, and iteration, remember that you’ll probably want all of this to be visible at some point, whether in a query or a backlog. Therefore, ….
Well, that wraps up this post on configuring Microsoft Azure DevOps. Ultimately, just think of each of these components as different ways to organize all the things you want to track in ADO. Next week, I’ll go over working with Boards. If you need to cath up, here are the other posts in the series.
- Managing Analytics Assets with ADO (aka how my org works and why we need ADO)
- Azure DevOps Terminology and Structure (so you know what we are talking about)
- Questions to Ask and Answer Before Configuring DevOps (so you don’t have rework like I did)
Pingback: Clone Processes to Unlock Customization in Azure DevOps » The Analytics Corner
Pingback: How to Update an Excel File with Power Automate Desktop » The Analytics Corner
Pingback: Use Azure DevOps Boards to Manage Analytics Assets » The Analytics Corner